MySQL分布式锁
mysql中提供了两个函数——get_lock('key', timeout)和release_lock('key')——来实现分布式锁,可以根据key来加锁,这是一个字符串,可以设置超时时间(单位:秒),当调用release_lock('key')或者客户端断线的时候释放锁。
mysql> select get_lock('user_1', 10);
-> 1
mysql> select release_lock('user_1');
-> 1
它们的使用方法如下:
get_lock('user_1', 10)如果10秒之内获取到锁则返回1,否则返回0;
release_lock('user_1')如果该锁是当前客户端持有的则返回1,如果该锁被其它客户端持有着则返回0,如果该锁没有被任何客户端持有则返回null;
例子见
https://www.cnblogs.com/tong-yuan/p/11616782.html
总结
mysql分布式锁的优点
- 方便快捷,因为基本每个服务都会连接数据库,但不是每个服务都会使用redis或者zookeeper;
- 如果客户端断线了会自动释放锁,不会造成锁一直被占用。
- mysql分布式锁是可重入的,对于旧代码的改造成本低。
mysql分布式锁的缺点
- 加锁直接达到数据库,增加了DB压力。
- 加锁的线程会占用一个session,也就是一个连接数,如果并发量大可能会导致正常执行的sql语句获取不到连接;
- 相对于redis或者zookeeper分布式锁,效率相对要低一些;
Redis分布式锁
实现锁的条件
- 状态(共享)变量,它是有状态的,这个状态的值标识了是否已经被加锁,在ReentrantLock中是通过控制state的值实现的,在ZookeeperLock中是通过控制子节点来实现的;
- 队列,它是用来存放排队的线程,在ReentrantLock中是通过AQS的队列实现的,在ZookeeperLock中是通过子节点的有序性实现的;
- 唤醒,上一个线程释放锁之后唤醒下一个等待的线程,在ReentrantLock中结合AQS的队列释放时自动唤醒下一个线程,在ZookeeperLock中是通过其监听机制来实现的;
实现锁的必要条件只有第一个,对共享变量的控制,如果共享变量的值为null就给他设置个值(java中可以使用CAS操作进程内共享变量),如果共享变量有值则不断重复检查其是否有值(重试),待锁内逻辑执行完毕再把共享变量的值设置回null。
说白了,只要有个地方存这个共享变量就行了,而且要保证整个系统(多个进程)内只有这一份即可。
这也是redis实现分布式锁的关键
Redis分布式锁怎么实现
从最简单的开始
可以使用setnx,set if not exists,表示如果key不存在,才会设置它的值,否则什么都不做。
两个客户端进程可以执行这个命令,达到互斥,就可以实现一个分布式锁。
客户端1申请加锁,加锁成功:
127.0.0.1:6379> SETNX lock 1
(integer) 1 // 客户端1,加锁成功
客户端2申请加锁,枷锁失败:
127.0.0.1:6379> SETNX lock 1
(integer) 0 // 客户端2,加锁失败
释放锁:
127.0.0.1:6379> DEL lock // 释放锁
(integer) 1
整体思路:

以上存在的问题是如果客户端1拿到锁后,业务处理逻辑复杂或者进程挂了没有释放锁,就会导致死锁,客户端2永远拿不到锁。
避免死锁
在 Redis 中实现时,就是给这个 key 设置一个「过期时间」。这里我们假设,操作共享资源的时间不会超过 10s,那么在加锁时,给这个 key 设置 10s 过期即可:
127.0.0.1:6379> SETNX lock 1 // 加锁
(integer) 1
127.0.0.1:6379> EXPIRE lock 10 // 10s后自动过期
(integer) 1
这样存在的问题就是两条命令不能保证原子操作,也就是不能保证两条命令都能执行,expire存在网络问题或Redis当即或客户端崩溃的情况不能执行。
如何优化?
使用一条命令
// 一条命令保证原子性执行
127.0.0.1:6379> SET lock 1 EX 10 NX
OK
EX,过期时间,单位秒
PX,过期时间,单位毫秒
NX,not exist,如果不存在才设置成功
XX,exist exist?如果存在才设置成功
试想这样一种场景:
- 客户端 1 加锁成功,开始操作共享资源
- 客户端 1 操作共享资源的时间,「超过」了锁的过期时间,锁被「自动释放」
- 客户端 2 加锁成功,开始操作共享资源
- 客户端 1 操作共享资源完成,释放锁(但释放的是客户端 2 的锁)
但是这里存在两个严重的问题:
- 锁过期:客户端1操作共享变量太久,超过了锁过期时间,导致锁被自动释放,之后被客户端2持有。
- 释放别人的锁:客户端1操作共享资源完成后,却又释放了客户端2的锁。
解决方案:
- 锁过期,无法彻底解决。
- 释放别人的锁。
解决办法是:客户端在加锁时,设置一个唯一标识进去。
例如,可以是自己的线程ID,也可以是一个UUID(随机且唯一)
// 锁的VALUE设置为UUID
127.0.0.1:6379> SET lock $uuid EX 20 NX
OK
这里假设 20s 操作共享时间完全足够,先不考虑锁自动过期的问题。
因为 Redis 处理每一个请求是「单线程」执行的,在执行一个 Lua 脚本时,其它请求必须等待,直到这个 Lua 脚本处理完成,这样一来,GET + DEL 之间就不会插入其它命令了。

// 判断锁是自己的,才释放
if redis.call("GET",KEYS[1]) == ARGV[1]
then
return redis.call("DEL",KEYS[1])
else
return 0
end
总结:
- 加锁: SET lock_key $unique_id EX $expire_time NX
- 操作共享资源。
- 释放锁:Lua脚本,先GET判断是否归属自己,再DEL释放锁。

锁过期时间不好评估怎么办
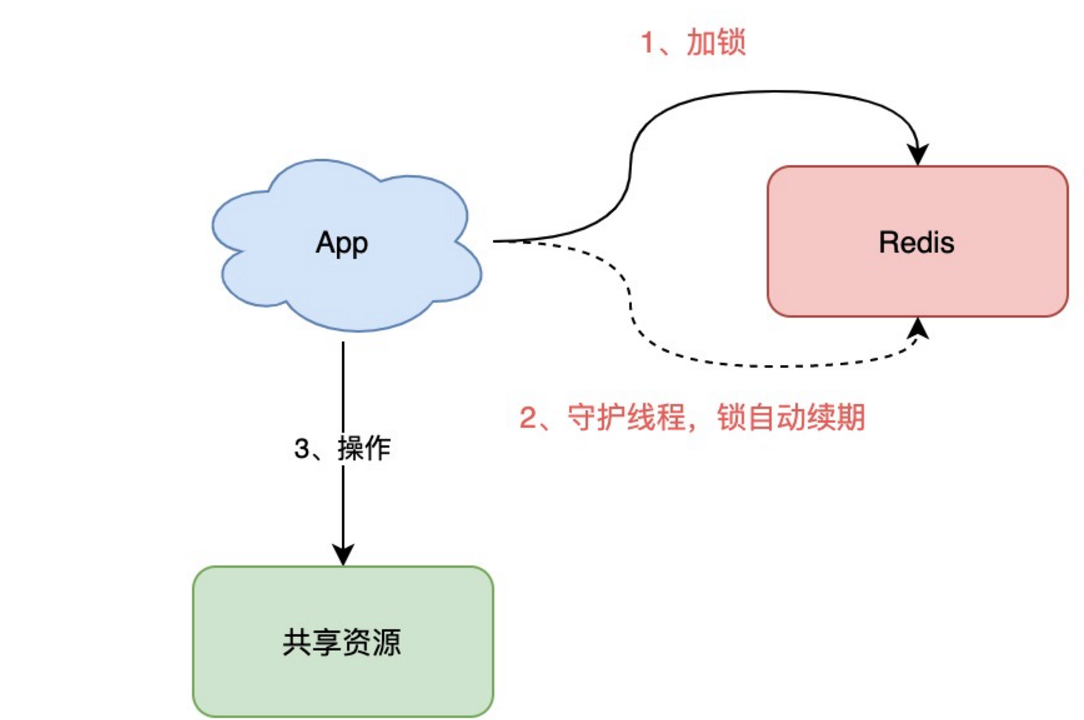
是否可以设计这样的方案:加锁时,先设置一个过期时间,然后我们开启一个「守护线程」,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行「续期」,重新设置过期时间。
这是一种比价好的方案。
已经有一个库把这些工作都封装好了:Redisson。
Redisson 是一个 Java 语言实现的 Redis SDK 客户端,在使用分布式锁时,它就采用了「自动续期」的方案来避免锁过期,这个守护线程我们一般也把它叫做「看门狗」线程。
除此之外,这个SDK还封装了很多易用的功能:
- 可重入锁
- 乐观锁
- 公平锁
- 读写锁
- Readock(红锁)
Redlock
Redlock解决方案
我们在使用 Redis 时,一般会采用主从集群 + 哨兵的模式部署,这样做的好处在于,当主库异常宕机时,哨兵可以实现「故障自动切换」,把从库提升为主库,继续提供服务,以此保证可用性。
那当「主从发生切换」时,这个分布锁会依旧安全吗?
试想这样的场景:
- 客户端 1 在主库上执行 SET 命令,加锁成功
- 此时,主库异常宕机,SET命令还未同步到从库上(主从复制是异步的)
- 从库被哨兵提升为新主库,这个锁在新的主库上,丢失了!
Redlock解决了以上场景。
Redlock真的安全吗
Redlock 的方案基于 2 个前提:
- 不再需要部署从库和哨兵实例,只部署主库。
- 但主库要部署多个,官方推荐至少 5 个实例。
也就是说,想用使用 Redlock,你至少要部署 5 个 Redis 实例,而且都是主库,它们之间没有任何关系,都是一个个孤立的实例。
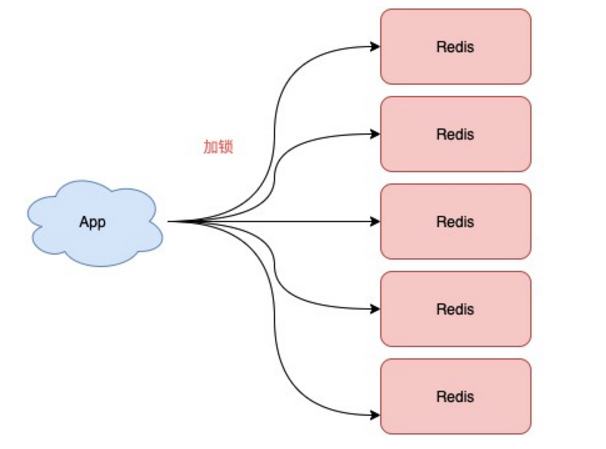
Redlock整体工作流程总共分五部:
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 >=3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
有4个重点:
- 客户端在多个 Redis 实例上申请加锁
- 必须保证大多数节点加锁成功
- 大多数节点加锁的总耗时,要小于锁设置的过期时间
- 释放锁,要向全部节点发起释放锁请求